Für die Huffman-Codierung werden die Daten, die im lossless mode aus der DPCM hervorgehen, unverändert übernommen. Aus der DCT hervorgehende Werte werden zunächst auf besondere Weise transformiert, um eine gut Huffman-codierbare Codefolge zu erhalten.
Dazu gibt es für DC- und AC-Koeffizienten verschiedene Verfahrensweisen. Der DC-Koeffizient wird zunächst mittels DPCM, wobei der Bezugspunkt der DC-Koeffizient des vorhergehenden Blocks ist, codiert, und danach in einen VLI-Wert umgewandelt.
Die AC-Koeffizienten werden in einer besonderen Darstellung verschlüsselt. Die entstehenden Werte haben die Form
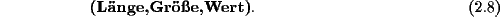
Dabei ist Länge eine 4-Bit Zahl und entspricht der Anzahl von Nullen bis zum nächsten Nicht-Null-Koeffizienten, Größe gibt die Anzahl der Bits an, die der Wert des Nicht-Nullkoeffizienten in VLI-Darstellung benötigt. Danach gibt Wert den Wert des Koeffizienten explizit an. Durch die Begrenzung auf vier Bit können hierbei maximal fünfzehn Zeichen auf einmal verkörpert werden.
Aus dieser Darstellung erkennt man, daß es am vorteilhaftesten ist, wenn möglichst lange Folgen von Nullen codiert werden müssen. Nun wird auch klar, warum die Koeffizienten entlang einer Zick-Zack-Kurve (Bild ![]() ) codiert werden. Nach der Umwandlung von der Matrixform in einen sequentiellen Bitstrom sind die AC-Koeffizienten so sortiert, daß die Koeffizienten der niedrigeren Frequenzen sich am Anfang befinden, und die der höheren Ortsfrequenzen am Ende. Da aber die Werte für höhere Frequenzen meistens verschwinden, entstehen oft lange ,,Null``-Folgen.
) codiert werden. Nach der Umwandlung von der Matrixform in einen sequentiellen Bitstrom sind die AC-Koeffizienten so sortiert, daß die Koeffizienten der niedrigeren Frequenzen sich am Anfang befinden, und die der höheren Ortsfrequenzen am Ende. Da aber die Werte für höhere Frequenzen meistens verschwinden, entstehen oft lange ,,Null``-Folgen.
Unter diesen Nullsequenzen gibt es wiederum zwei mit besonderer Bedeutung. Eine Nullenfolge die bis zum Ende des Blocks geht, außer wenn der Beginn der Sequenz mit dem Ende des Blocks zusammenfällt, wird nur als Blockendemarke (end-of-block, EOB) codiert. Diese Codierung hat die Form  .
.  wird hierbei nicht angegeben. Codierte Werte der Form
wird hierbei nicht angegeben. Codierte Werte der Form  haben Nullsequenzen, die länger als fünfzehn Zeichen sind. Auch hier wird auf eine Codierung des Wertes verzichtet (0 wird implizit angenommen) und sofort die nächste Sequenz verschlüsselt. Damit sind maximal 4 Darstellungen der Form (Länge,Größe) direkt hinter möglich, wobei allerdings nach der vierten angegeben sein muß.
haben Nullsequenzen, die länger als fünfzehn Zeichen sind. Auch hier wird auf eine Codierung des Wertes verzichtet (0 wird implizit angenommen) und sofort die nächste Sequenz verschlüsselt. Damit sind maximal 4 Darstellungen der Form (Länge,Größe) direkt hinter möglich, wobei allerdings nach der vierten angegeben sein muß.
Nach dieser Transformation erfolgt die eigentliche Huffman-Codierung. Die zu codierenden Daten werden zunächst hinsichtlich ihrer statistischen Zusammensetzung untersucht, indem eine Tabelle erstellt wird, die jedem Symbol die Häufigkeit seines Auftretens im Datenmaterial zuordnet. Ausgehend von dieser Häufigkeitstabelle erstellt der Algorithmus eine Huffman-Tabelle in der jedem auftretenden Symbol ein neuer, ,,digitalisierter`` Wert zugeordnet wird. Der daraus resultierende Huffman-Code hat eine um so kompaktere Form, je häufiger das Symbol im Ausgangscode vorkommt.
Die explizite Bestimmung der Huffman-Tabelle muß nicht immer erfolgen. In vielen Fällen sind bereits vorgefertigte, aufgrund statistischer Erfahrungswerte erstellte Tabellen ausreichend. Um jedoch das Beste aus der Huffman-Codierung herauszuholen, kann man auf eine Generierung der Tabellen nicht verzichten.
Die Effizienz des Huffman-Codes hängt einerseits von der Größe des zu codierenden Alphabets, also der Menge der vorkommenden Symbole, als auch von der stochastischen Verteilung der Daten ab. Sind die Daten ungefähr gleich verteilt, ist der Huffman-Algorithmus nicht sehr effizient und die Komprimierungsraten entsprechend niedrig.